Learn from Data Breaches: Real-World Security Incidents

Learning from Real-World Cybersecurity Incidents
Real-world security incidents are concrete examples of how cybersecurity failures unfold in operational environments and why organisations must treat prevention and response as strategic priorities. Current analysis from 2024 highlights that breaches and attacks increasingly impose long-term operational and reputational costs on affected organisations, reinforcing the value of learning from documented cases to improve resilience. This article explains what constitutes a high-impact security incident, examines representative case studies across data breaches and ransomware, and distils practical lessons that map directly to controls, standards and operational actions. Readers will learn typical attack vectors, the human and supply-chain factors that enable incidents, and a step-by-step approach to prevention and response that aligns with ISO 27001 principles, incident response best practice and forensic evidence workflows. The piece closes by outlining how organisations can operationalise these lessons through incident response planning and emerging defences such as Zero Trust and AI-aware monitoring. Throughout, the content uses real-world examples, control mappings, and tangible checklists so security teams and decision-makers can prioritise the highest-impact mitigations.
What Are the Most Impactful Cybersecurity Incident Case Studies?
High-impact cybersecurity incidents demonstrate common systemic failures and reveal control gaps that other organisations can address proactively. Analysing major breaches shows recurring patterns—unpatched vulnerabilities, credential compromise, and vendor trust breakdowns—that attackers exploit to achieve large-scale data exfiltration or service disruption. Studying these incidents clarifies which technical and process controls most effectively reduce risk and helps translate abstract standards into operational tasks. The following compact comparison highlights representative incidents and the immediate lessons they provide for prevention and detection, setting up a deeper look at data breaches and ransomware examples below.
This table summarises illustrative incidents, their attack vectors, impacts and a one-line lesson for practitioners.
These comparisons show that while technical details differ, every case points to the same defensive priorities: visibility, timely patching, strict access controls and supply-chain vigilance. The next subsections draw out specifics for data breaches and ransomware to illustrate practical controls.
Which Major Data Breaches Have Shaped Information Security?
Major data breaches that shaped modern information security typically combine a single technical weakness with process failures that allow prolonged exposure. In representative incidents, attackers exploited unpatched services, weak authentication, or misconfigured cloud storage to access sensitive records at scale, which triggered regulatory scrutiny and costly remediation. For defenders, the critical countermeasures include strong identity and access management, automated patch management, and data discovery combined with encryption to reduce the value of stolen assets. Mapping these root causes to standards shows direct alignment with controls that require vulnerability management, access control policies and asset classification.
- Unpatched services: Attackers target known CVEs when patching programmes are weak.
- Weak authentication: Stolen credentials enable escalations and lateral movement.
- Misconfigurations: Clouds and storage misconfigurations expose data without detection.
These lessons lead naturally into prevention measures—particularly ISO-aligned controls and operational steps—that organisations should prioritise to reduce breach probability and impact.
What Lessons Can We Learn from Ransomware Attack Examples?
Ransomware incidents often begin with simple vectors such as phishing or compromised credentials and escalate quickly when networks lack segmentation and detection. Typical successful ransomware campaigns combine social engineering to gain initial access, credential theft to move laterally, and broad file encryption that disrupts operations. The practical recoverability strategies emphasise having immutable, offline backups, clearly defined recovery playbooks, and legal/insurance coordination to support decision-making. Prevention focuses on blocking initial access paths, implementing multi-factor authentication, and using endpoint detection that flags abnormal encryption activity.
Ransomware Resilience: Planning for High-Profile Incidents and Recovery
Insurance businesses have been depending more on digital infrastructures to manage their policies, process claims, manage their customer information, and money transfer activities. This reliance makes insurers vulnerable to advanced cyber-attacks, especially the ones involving ransomware that risks to paralyze operations, damaging sensitive information, and causing great financial and reputational damage. This paper discusses a comprehensive ransomware resilience and recovery planning strategy for insurance infrastructure. Starting with a threat landscape analysis provides us with a list of some popular ransomware or methods used to attack insurance systems. An analysis of high-profile incidents is conducted to gain insight into their impact on operations and the economy.
Ransomware Resilience and Recovery Planning for Insurance Infrastructure, GR Enjam, 2020
Further emphasizing the critical need for robust recovery strategies, research highlights the specific challenges and planning required for ransomware resilience, particularly within vulnerable sectors like insurance.
- Entry control: MFA and phishing-resistant authentication reduce initial access likelihood.
- Containment: Segmentation and rapid isolation limit lateral spread once detected.
- Recovery: Offline backups and tested recovery procedures shorten downtime and reduce leverage.
Understanding these trade-offs—such as whether to pay ransom—depends on a clear recovery posture, which is why the next sections examine root causes in more depth and how organisational processes tie into incident prevention.

How Do Information Security Failures Occur in Real-World Incidents?
Information security failures arise from interacting weaknesses across people, processes and technology that attackers chain together to achieve objectives. Root causes cluster into a few high-frequency categories: human error and social engineering, credential theft and inadequate access controls, exploited vulnerabilities and misconfigurations, and third-party/supply chain compromises. Each category describes a mechanism by which attackers convert a vulnerability into a breach, and each maps to specific controls and measurements that reduce likelihood or impact. Below we unpack the human factor and third-party risks, then connect those to specific mitigation steps.
The human element often provides the easiest path for attackers—phishing, misplaced attachments, and misdelivery cause many incidents—so training, simulation and reporting pathways are essential complements to technical controls. This leads directly into discussing employee-focused defences and vendor risk management.
What Role Does the Human Element Play in Cybersecurity Breaches?
Human-driven failures are a primary enabler in many breaches because social engineering bypasses purely technical defences and exploits routine workflows. Attackers craft convincing phishing messages or leverage poor credential hygiene to gain initial access, and insiders with excessive privileges can amplify impact unintentionally. Mitigation requires a mix of prevention and detection: mandatory phishing-resistant MFA, role-based access with least privilege, and ongoing security awareness programmes that include realistic simulations and measured metrics. Organisations should track phish-click rates, time-to-report and reductions in risky behaviour as leading indicators of improved security posture.
- Phishing resistance: Implement phishing-resistant MFA and simulate attacks regularly.
- Access governance: Apply least privilege and periodic entitlement reviews to reduce over-privileged accounts.
- Reporting culture: Encourage rapid reporting and provide clear escalation pathways to detect compromises early.
Solid human-focused controls reduce the probability that an attacker can convert a single error into a full-scale incident, and they complement technical controls discussed in subsequent sections.
How Do Third-Party Risks and Supply Chain Attacks Contribute to Failures?
Supply-chain and third-party compromises occur when organisations implicitly trust vendor software, managed services or integrations without sufficient assurance and monitoring. Attackers targeting a widely used vendor can gain a pivot into multiple customer environments, and weak contractual security requirements or lack of supplier segmentation magnify impact. Effective vendor risk management includes pre-engagement security assessments, contractual security SLAs, and technical segregation (network and credential separation) for third-party access. Continuous monitoring of vendor telemetry and tightly scoped access reduce the likelihood that a vendor compromise becomes an organisational breach.
- Vendor assurance: Require evidence of secure development and update practices from critical suppliers.
- Contract controls: Insert security requirements and audit rights into supplier agreements.
- Technical segmentation: Treat vendor access as untrusted; isolate and monitor connections.
Understanding third-party risk completes the view of failure modes and naturally points to prevention strategies—standards, training, and controls—that organisations can adopt.

What Are Effective Strategies for Preventing Cyber Incidents?
Effective prevention bundles technical controls, process discipline and continuous improvement into a coherent programme that reduces both likelihood and impact of incidents. Core measures include adopting an ISMS aligned with ISO 27001, implementing robust identity and access controls, maintaining a disciplined patch and configuration management process, deploying backups and segmentation for resilience, and running continuous detection and response capabilities. The practical HowTo checklist below summarises immediate actions security teams can adopt to harden their environment and align to regulatory expectations.
- Establish an ISMS: Define scope, risk assessment processes and continual improvement cycles.
- Harden access: Enforce MFA, least privilege and session management.
- Operational hygiene: Automate patching, configuration scanning and asset inventory.
- Resilience: Maintain offline backups and recovery runbooks; test restore procedures.
- Supply-chain controls: Vet suppliers and enforce contractual security requirements.
These steps map directly to controls found in modern frameworks and provide measurable improvements in readiness—next, we show ISO 27001 controls mapped to practical implementations and include a short service note.
Before the ISO control table, a brief note: the following mapping connects specific ISO 27001 controls to hands-on measures organisations can implement to reduce incident risk. After this practical guidance, readers seeking implementation support should consider expert help to accelerate certification and align controls with operations.
This table demonstrates how ISO 27001 controls translate into operational tasks that reduce breach vectors and support audit-readiness; organisations that map controls this way can prioritise implementable steps before pursuing certification.
How Does ISO 27001 Certification Enhance Incident Prevention?
ISO 27001 provides a management-system approach that turns ad hoc security work into a repeatable cycle of risk assessment, control implementation and continuous improvement. By formalising asset identification, threat modelling and control selection, ISO 27001 helps organisations prioritise mitigations with measurable objectives and audit trails. Practically, certification increases discipline around patching, access control, supplier assurance and evidence collection, and it demonstrates due diligence to partners and regulators. For many organisations, external guidance accelerates ISMS build-out and positions them to respond faster when incidents occur.
ISO 27001 Effectiveness in Preventing Real-World Security Incidents
The effectiveness of ISO 27001 is in preventing or minimizing the exposure to information security incidents in the real world. In a scenario where there has been so much investment in adopting the framework and subsequent certification resulting in high levels of stakeholder assurance, the focus is to identifying the areas where it is effective. But more importantly, it also focus on the areas where there are gaps, leading to information security risks and/or an incident even in a situation where the framework is adhered to and certification against it exists.
Effectiveness of ISO 27001, as an information security management system: an analytical study of financial aspects, NK Sharma, 2012
While ISO 27001 offers a robust framework, it’s also important to critically assess its real-world effectiveness and potential gaps in preventing all security incidents.
- ISMS lifecycle: Risk assessment → Treatment → Monitoring → Improvement.
- Control evidence: Documented policies and traceable implementation support audit readiness.
- Stakeholder confidence: Certification signals structured governance to customers and authorities.
For organisations that need operational support, ACATO offers ISO 27001 implementation and certification assistance delivered by certified experts, helping translate controls into practical processes and audit-ready evidence while explaining steps and costs during an initial free consultation. This operational support can reduce time-to-compliance and provide targeted remediation roadmaps aligned with business priorities.
Why Is Employee Security Awareness Training Critical for Defense?
Employee security awareness training turns the human element from a liability into an active layer of defence by teaching recognition of phishing, proper credential hygiene and reporting procedures. Effective programmes combine concise curriculum modules, role-specific training for high-risk users, and regular phishing simulations tied to measurable KPIs such as click-through rates and report rates. Delivery methods should mix short microlearning sessions with scenario-based exercises and post-simulation coaching for those who fail tests. Measuring programme success requires tracking reductions in risky behaviours, faster reporting times and fewer incidents attributable to social engineering.
- Core syllabus: Phishing recognition, password hygiene, reporting and data handling rules.
- Cadence: Quarterly micro-sessions plus ongoing simulated phishing campaigns.
- Metrics: Phish-click rate, mean time to report, and reduction in incidents linked to user error.
Embedding training into performance metrics and leadership communication closes the loop between awareness and operational security, and sets up more effective incident response when prevention fails.
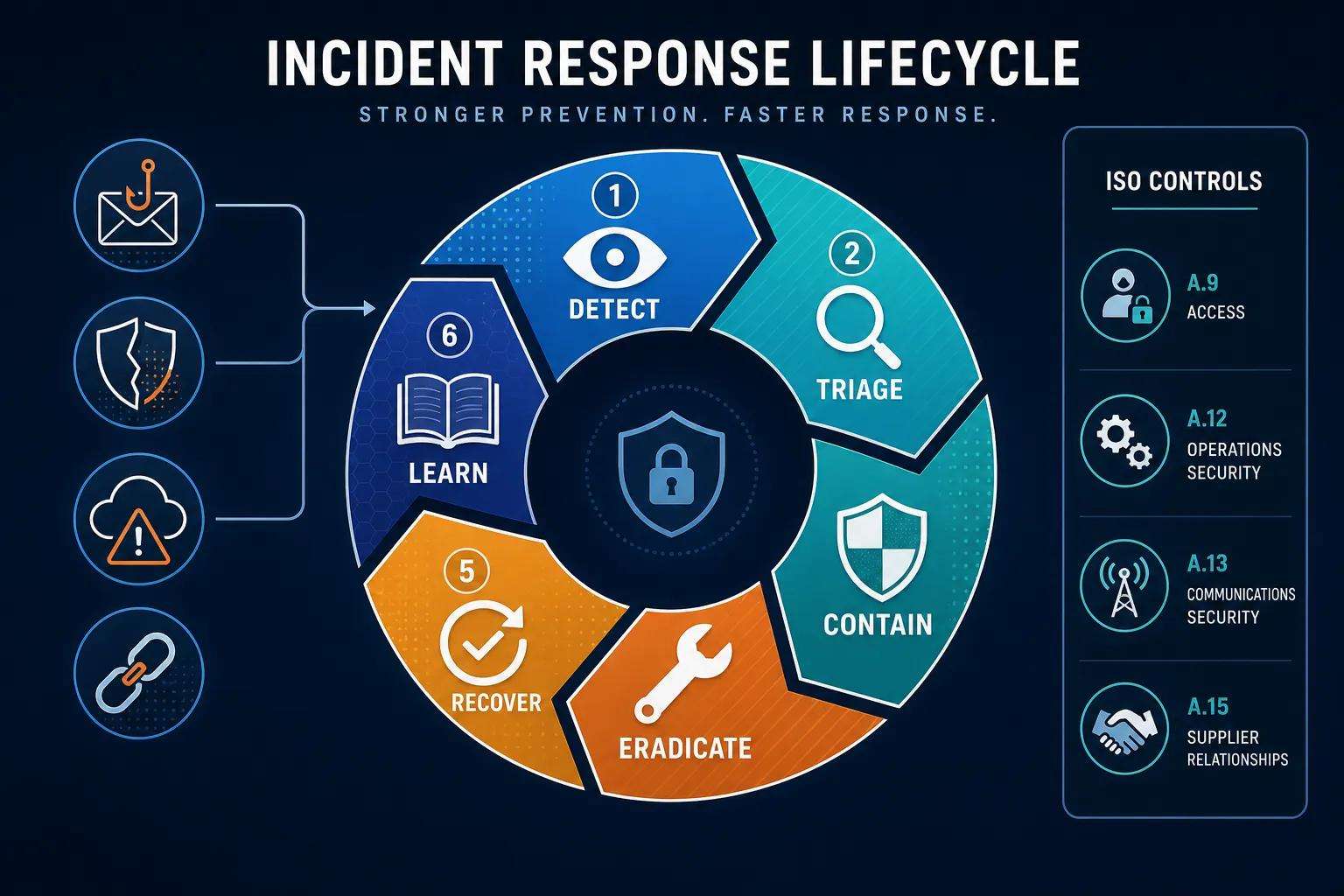
How Can Organizations Build Robust Incident Response and Recovery Plans?
A robust incident response (IR) plan defines phases, roles, communications and measurable outcomes so organisations can detect, contain and recover from incidents with minimal disruption. The IR lifecycle—detect, triage, contain, eradicate, recover and learn—provides a clear sequence of responsibilities and decision points that teams can rehearse. Key components include detection criteria, escalation paths, technical playbooks, communication templates for stakeholders and regulators, and regular tabletop exercises to validate assumptions. Below is an EAV-style table that maps IR components to responsibilities and measurable outcomes to help organisations assess gaps.
Before the table, note: this mapping helps translate high-level IR concepts into assignable tasks and metrics that leadership can track to improve readiness over time.
This table clarifies how each IR activity maps to a responsible group and the measurable outcomes that indicate improvement, enabling organisations to set realistic performance targets.
What Are the Key Components of an Effective Incident Response Plan?
An effective IR plan tightly defines detection criteria, escalation thresholds, containment playbooks and recovery procedures, and it assigns clear decision authority at each stage. Detection must include monitored telemetry, alert prioritisation and documented escalation workflows so that unusual activity triggers rapid investigation. Containment playbooks should specify isolation steps, credential resets and temporary access controls to stop propagation, while eradication details remediation tasks and validation checks. Recovery requires tested restore procedures, communication templates for regulators and customers, and predefined acceptance criteria to confirm service integrity. Finally, post-incident reviews must feed findings back into the ISMS and roadmaps for control improvements.
- Detection criteria: Define alert thresholds and required evidence before escalation.
- Containment playbooks: Provide executable runbooks for isolating affected segments.
- Post-incident learning: Assign remediation owners and verify closure of actions.
With these components in place, organisations improve response times and reduce operational and regulatory exposure after incidents, and this naturally leads to the role of forensics in underpinning those activities.

How Does IT Forensics Support Post-Incident Analysis and Recovery?
IT forensics preserves evidence, reconstructs timelines and identifies root cause, enabling accurate scope determination and supporting legal, regulatory and insurance processes. Forensic activities include securing volatile data, imaging affected systems, collecting logs and creating an attack timeline that links indicators of compromise to specific actions. The outputs—IOC lists, timeline reports and evidence packages—inform containment and remediation decisions and provide substantiation for breach notifications. Forensic analysis also quantifies data exposure to support impact assessment and remediation prioritisation.
- Evidence priorities: Volatile memory, system images, and centralized logs.
- Forensic outputs: IOCs, attack timeline, affected asset inventory.
- Stakeholder use: Regulators, insurers and legal teams rely on forensic reports for reporting and claims.
Operationalising forensics requires clear procedures and external capability where internal teams lack capacity. Where expert assistance is required, ACATO provides Incident Response and IT Forensics services to operationalise forensic collection and analysis and offers a free consultation to explain steps and likely costs. This support helps organisations accelerate containment, produce audits and meet reporting obligations with specialist evidence handling.
What Emerging Threats and Trends Should Organizations Prepare For?
Emerging threats in 2024 include AI-enabled attack automation, increased Shadow AI usage inside organisations, broader adoption of Zero Trust architectures, and evolving regulatory landscapes such as NIS 2.0 that raise incident reporting and supplier risk requirements. These trends change both attacker capabilities and defender priorities: attackers can scale social engineering and adapt payloads faster, while defenders must deploy model governance, behavioural detection and architecture changes that reduce implicit trust. Preparing requires updated detection use-cases, controls for model and data governance, and a roadmap for Zero Trust adoption that aligns with regulatory duties. The following subsections expand on AI impacts and practical Zero Trust / NIS 2.0 actions.
This trend analysis frames strategic investments and operational updates that security leaders must prioritise to remain resilient.
How Is AI Changing Cyber Attacks and Defense Mechanisms?
AI is accelerating both attack sophistication and defensive detection: attackers use generative models to craft personalised phishing, automate reconnaissance and optimise payloads, while defenders use AI for anomaly detection, triage and automated response orchestration. This arms race means organisations must govern internal model use, monitor for Shadow AI activity that exfiltrates data and apply DLP around model inputs and outputs. Defensively, integrating ML-based detection into triage pipelines reduces mean time to detect, while human-in-the-loop processes ensure high-fidelity responses. Model governance, data classification and monitoring of AI tool use are essential mitigations.
AI-Driven Cyber Attacks: Case Studies and Defense Strategies
This article explores the burgeoning landscape of AI-driven cyber-attacks and the corresponding AI-powered cybersecurity defenses. Through an extensive literature review, we establish a foundational understanding of current AI techniques used in cyber-attacks, such as machine learning-based malware and AI-generated phishing schemes. Concurrently, we examine state-of-the-art AI-driven defense mechanisms, including anomaly detection systems and automated response strategies. To provide concrete examples, we conduct detailed case studies of high-profile cyber incidents where AI played a pivotal role. These case studies illustrate the sophistication and effectiveness of AI-driven attacks and highlight the defensive measures deployed to counteract them.
Bridging the AI divide: The evolving arms race between AI-driven cyber attacks and AI-powered cybersecurity defenses, 2024
This evolving landscape underscores the ongoing arms race between AI-driven attacks and AI-powered defenses, necessitating continuous adaptation and strategic investment.
- Attacker uses: Personalized phishing, automated vulnerability discovery.
- Defender uses: Anomaly detection, prioritisation and automation of containment.
- Governance: Shadow AI controls, DLP for model inputs and incident monitoring for AI misuse.
Adapting to AI-driven changes requires both technical controls and policy updates to ensure the benefits of AI tools do not become new avenues for exfiltration or compromise.
What Are the Implications of Zero Trust Architecture and NIS 2.0 Compliance?
Zero Trust shifts the security model from implicit network trust to continuous verification of identity, device posture and policy enforcement, which reduces lateral movement and limits the impact of compromised credentials. Practical Zero Trust steps include least-privilege access, strong device hygiene, micro-segmentation and continuous policy evaluation. At the same time, NIS 2.0 increases reporting obligations and supplier oversight in many jurisdictions, requiring clearer incident reporting processes and stronger vendor risk controls. Prioritising Zero Trust alignment with NIS 2.0 objectives—enhanced logging, supplier assurance, and rapid reporting—helps organisations meet regulatory expectations while improving operational security.
- Zero Trust steps: Enforce identity verification, device posture checks and micro-segmentation.
- NIS 2.0 priorities: Incident reporting capability, supplier oversight and documented security governance.
- Combined approach: Use Zero Trust to reduce incident impact and technical barriers to rapid, accurate reporting.
Organisations that align architecture upgrades with compliance planning will both reduce operational risk and simplify regulatory response when incidents occur.
Real-world incidents offer clear, repeatable lessons: reduce trust, increase verification and document evidence and plans for rapid action. Acting on these lessons now—through controls, training and tested response plans—improves resilience and reduces long-term costs and disruption. For organisations seeking implementation support, ACATO provides certified experts in cyber security, IT forensics, incident response and ISO certification who can help translate these strategies into operational programmes and offer a free consultation to explain next steps and likely costs.